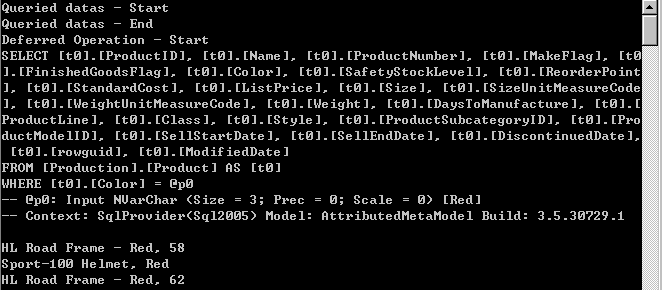
public void SearchForType()
{
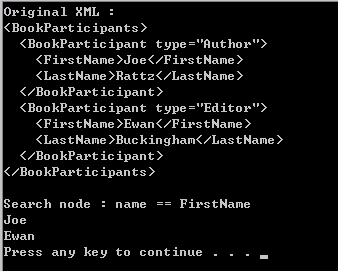
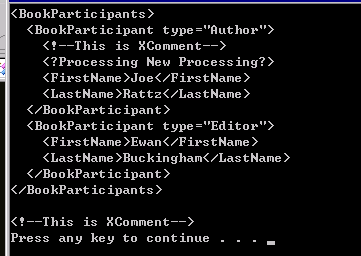
XDocument xDocument = new XDocument(
new XElement("BookParticipants",
new XElement("BookParticipant",
new XAttribute("type", "Author"),
new XComment("This is XComment"),
new XProcessingInstruction("Processing", "New Processing"),
new XElement("FirstName", "Joe"),
new XElement("LastName", "Rattz")),
new XElement("BookParticipant",
new XAttribute("type", "Editor"),
new XElement("FirstName", "Ewan"),
new XElement("LastName", "Buckingham"))));
Console.WriteLine(xDocument.ToString());
Console.WriteLine();
var elements = xDocument.Element("BookParticipants").
Elements("BookParticipant").Nodes().OfType<XComment>();
foreach(var element in elements)
{
Console.WriteLine(element);
}
}